快速链接
表征的微调方法
2024年4月5日
ReFT跟现有的PEFTs(参数高效微调)有啥区别?
模型表征 (Representations) 是不具有参数的。 现有的PEFTs通常需要训练一些少量的模型参数,或者对于新加的适配器 (Adaptor) 进行少量的参数微调,或者像前缀词 (Prefix) 微调一样训练少量词向量。表征本身并不具有任何参数,他们是模型在线生成的产物。因此,我们加入了表征干预模块这个概念。这个干预模块负责修改特定的表征从而达到训练的目标。干预的表征通常是很少量的分词 (tokens) 所在位置的表征,帮助我们省训练参数。
输入序列中的时间概念是关键。 现有的PEFTs,也包括最近的RED [0] 通常忽略时间这个概念,而是对于模型产生的表征进行全局修改。换言之,每一层,每一个分词对应的表征全部都会产生变化以达到训练的目标。我们认为这是没必要的。大语言模型的表征通常已经具有十分有意义的表示,比如词在空间向量中的位置和词的意思通常会有相关性等。所以,我们猜想,如果我们只是对少部分表征进行修改,是不是也能达到训练的目标呢?
模型和解释性为我们的方法提供了理论基础。 在ReFT之前,其实就有一些表征修改的方法从而达到控制模型输出的能力。但跟他们不一样的地方是,我们的LoReFT方法是基于线性子空间这个概念。线性子空间来源于早期神经网络的工作,比如最著名的PDP的几篇鼻祖文章 [1][2][3]。这些文章都提出一个假说就是神经网络学习到的概念 (Concept) 都存在于线性子空间中。基于这些理论基础,我们的方法会在表征的线性子空间中进行修改,命名为LoReFT。
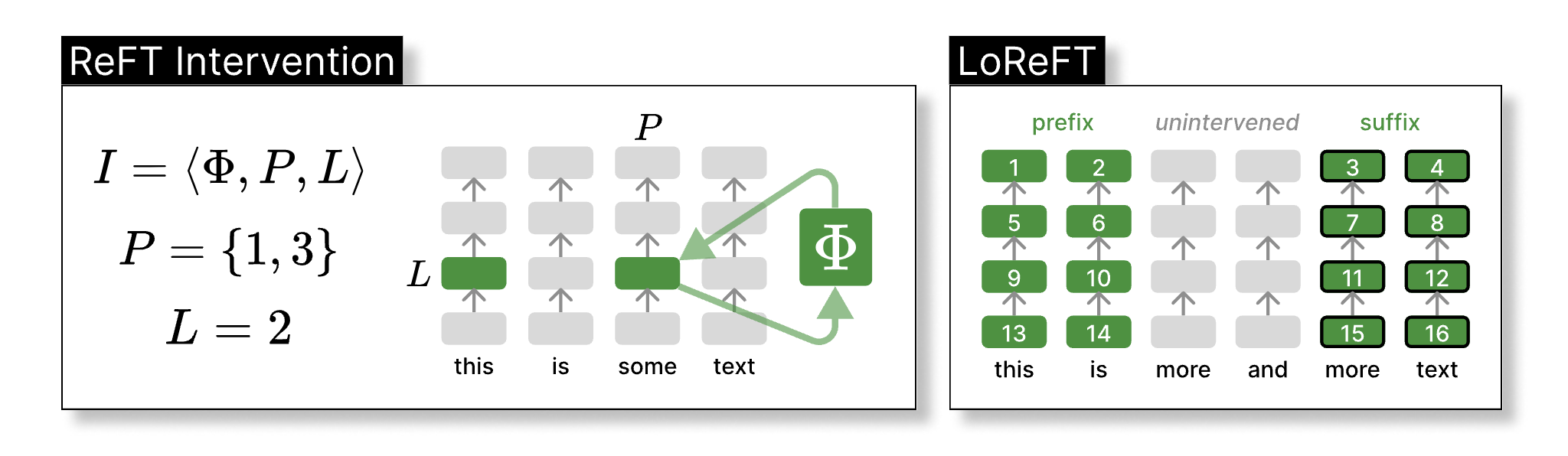
在上面的图中 I 代表了我们的干预模块,方程 Φ 就是我们需要学习的表征干预方程,P 和 L 分别代表了干预位置,和干预层。在右边图中,我们详细标注了我们具体在什么位置进行干预(这里的位置包含了分词位置和模型层号)。在这个示意图里,我们干预了前两个,和后两个分词对应的所有层的表征。
我们对于ReFT的表现预期,并没有很高。
对于特定位置的表征修改存在两个可能的问题:(1)可能会特别容易过拟合,训练极其不稳定。(2)也有可能根本不能进行长输出的控制,因为我们只是在干预输入的提示词(Prompt)而已。我们对于ReFT的最后表现是持有惊讶的态度。
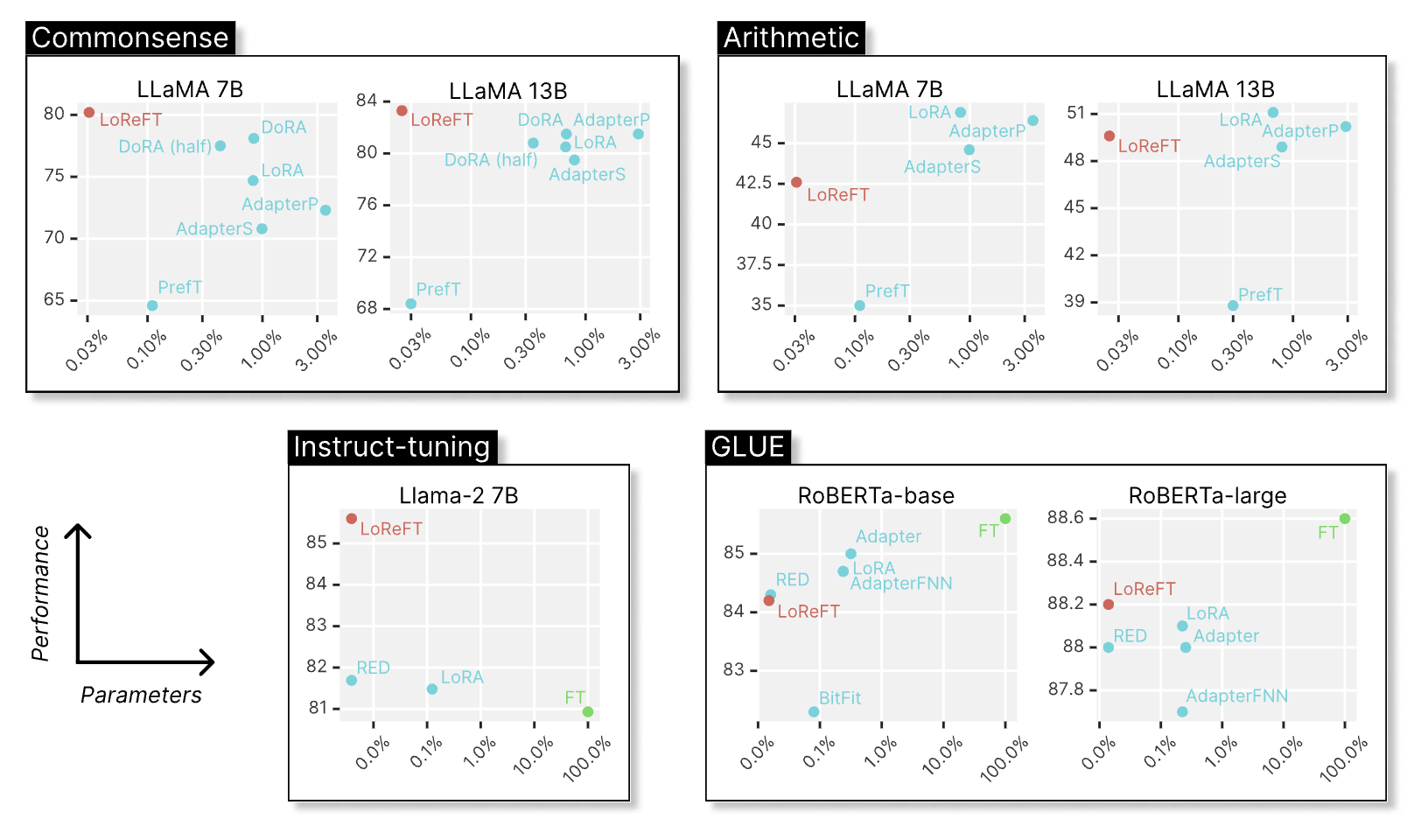
在我们这些实验当中,最令人满意的是我们的语言模型的对齐训练。我们满意的不是LoReFT在我们的测试当中跑的最好,而是在这组LoReFT实验当中,我们只修改了32层其中4层的表征,并且每一个修改都是低秩矩阵,秩为4。我们在补充实验当中用了仅1000个训练样本,26.2万参数,训练基础语言模型18分钟就达到了不错的对齐效果(p.s.应该可以更加高效)。
LoReFT较为出色的表现说明了什么呢?
预训练很有可能是赋予模型能力的关键,而不是后期微调。 一个重大的假设是,预训练阶段赋予了基础语言模型所有的能力,而微调仅仅像是一种风格转换,将模型定位到正确的输出空间。特别是对于指令调优,它似乎最有可能是风格转换。
对提示词的干预影响长篇生成。这是出乎意料的。在我们所有的实验中,我们只对提示词进行干预,但我们控制了所有生成的词。为什么这个可以有效呢?可能是因为要控制模型的生成,你只需要将一些最初的提示词的表征置于正确的状态。你的语言模型是你的未来透镜 (Future Lens),用于从隐藏表示中解码词。
线性子空间具有强大的能力,但它的能力取决于模型的上游计算。 LoReFT表明,线性子空间包含丰富的语义,你可以操作这些语义来引导模型行为。更重要的是,这些干预不仅导致了表示中的变化,还导致了所有上游计算的变化(即,干预表示的右上角计算的所有变化)。你可以将LoReFT视为它在强化或削弱现有的因果路径。
LoReFT为什么能够有效呢? 一个有趣的记忆力测试。
简而言之,我们目前还不确定。我们只是通过记忆测试定性地研究其限制,希望能更好地理解ReFT。我们首先简化我们的干预函数Φ,通过移除Wh项并且只学习偏置项,使其参数比原始LoReFT更少:
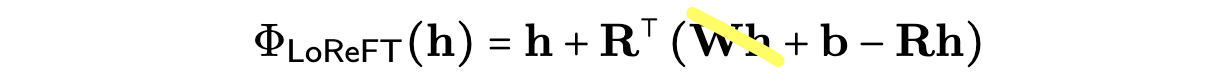
然后,我们用一个示例,训练一个秩为1的LoReFT。给定一个固定的非英文提示,我们训练这个干预来恢复书籍《爱丽丝梦游仙境》的开头。换句话说,我们想测试单个秩为1干预能够"存储"多少单词。

上图显示了前缀恢复率(Rec. %)作为完全匹配的情况。如果是100%,这意味着文本被完全恢复了。我们在每个测试中改变需要记忆的长度和干预层。令人惊讶的是,秩为1的LoReFT在LLaMA-1 7B上可以记忆多达2048个分词,几乎适用于所有层。这意味着语言模型非常擅长解包存储在表示中的信息 - 语言模型本身,就是超级强大的未来透镜。
LoReFT在向量空间中操作,可能是可组合的。
像LoRA这样的PEFT提供了一些事后的酷炫解释性用途,例如权重合并,这也已经在学习到的模型权重中尝试过 [4] [5]。LoReFT能做类似的事情吗?是的,ReFT可以以非常可解释的方式组合,因为LoReFT学习正交子空间。
分别学习子空间,然后进行组合。在这个实验中,我们分别为不同的任务训练了两组子空间:(1)给定英语提示的德语句子完成任务和(2)英语指令跟随任务。在推理时,我们对这两组进行干预。

如上例所示,我们干预后的模型可以开始遵循英语指令,但通过将两种能力组合在一起,用德语回答。
来试试LoReFT吧!可直接用我们开发的库 pyreft!
为了降低从PEFTs库到ReFT的切换成本,我们构建了一个pyreft-native Python库, pyreft. 我们使接口就像任何其他PEFTs库一样。以下代码展示了如何配置一个干预过的LLaMA模型:

一些疑惑和感受:ReFTs、可解释性、抽象化和控制。
更多的ReFTs。 ReFTs允许我们跨不同的时间步和位置进行干预。到目前为止,我们只对提示词进行干预。当我们跨层进行干预时,我们不共享权重。我们也尚未尝试进行更为复杂的干预,比如在特定的因果路径上进行干预(例如,在第7层的第0个位置的注意力头8和第8层的第1个位置的注意力头9)。更复杂的ReFTs或自动ReFTs会更好 (参考AdaLoRA [6])。拥有更好控制数学推理能力的ReFTs会很酷。
可解释性。 ReFT依赖于解释性工作的洞见,它也可能能够反过来为该领域贡献洞见。我们希望ReFT能够说服你,当一起同时干预过个表征时,神经元 (Neurons) 可以同时完成许多任务。这也让我们思考,将一组功能性词汇分配给描述单个神经元编码的内容,或一组神经元编码的内容,是否合理。它们甚至可能在给定不同提示的情况下编码不同的事物。更重要的是,它们编码的内容在很大程度上取决于它们所参与的上游计算。我们希望我们能够用一个更积极的视角解读我们的模型。而不是将它们视为我们可以修剪和理解的静态参照物。我们可以从模型中创建有用且可解释的抽象。
因果抽象和模型控制。 对齐训练可以通过SFT或SFT加上一些奖励建模来完成。我们希望ReFT展示对齐也可以通过干预训练或编辑表示来完成。通过微调表征,你本质上是在创建一个抽象,即一个你有部分控制权的灰盒模型,前提是你知道模型在干预条件下的行为方式。换句话说,你能做的因果抽象越多,你获得的控制就越多。
其他想法。 ReFT达到或非常接近于SoTA是出乎意料的。这意味着我们的LM在它们的表示空间中有更多的潜力可以被探索。我们也希望ReFT不仅被视为另一种PEFT方法以供你未来的工作进行基准测试,而且是我们为了研究我们的LM如何工作以及它们的极限提供一些更多的思路。
引用本文
参考文献
BibTeX
感谢
我们感谢Jing Huang在设计我们的记忆测试以及写作上的有益讨论。我们感谢Chenglei Si, Harshit Joshi, Jordan Juravsky, Julie Kallini, Ken Liu, Rohan Pandey, Jiuding Sun, Leonard Tang, Tristan Thrush, Shengguang Wu, Qinan Yu, Yanzhe Zhang, Amir Zur, 和 Shiqi Chen对该项目的有益讨论和对手稿的评论。